FRNN¶
- class frlearn.classifiers.FRNN(*, upper_weights: ~typing.Callable[[int], ~numpy.array] = LinearWeights(), upper_k: int = <function at_most.<locals>._f>, lower_weights: ~typing.Callable[[int], ~numpy.array] = LinearWeights(), lower_k: int = <function at_most.<locals>._f>, dissimilarity: str = 'boscovich', nn_search: ~frlearn.neighbours.neighbour_search_methods.NeighbourSearchMethod = <frlearn.neighbours.neighbour_search_methods.KDTree object>, preprocessors=(<frlearn.statistics.feature_preprocessors.RangeNormaliser object>,))[source]¶
Implementation of Fuzzy Rough Nearest Neighbour (FRNN) classification.
- Parameters
- upper_weights(int -> np.array) or None = LinearWeights()
OWA weights to use in calculation of upper approximation of decision classes. If None, only the upper_kth neighbour is used.
- upper_k: int or (int -> float) or None = at_most(20)
Effective length of upper weights vector (number of nearest neighbours to consider). Should be either a positive integer, or a function that takes the class size n and returns a float, or None, which is resolved as n. All such values are rounded to the nearest integer in [1, n]. Alternatively, if this is 0, only the lower approximation is used.
- lower_weights(int -> np.array) or None = LinearWeights()
OWA weights to use in calculation of lower approximation of decision classes. If None, only the lower_kth neighbour is used.
- lower_k: int or (int -> float) or None = at_most(20)
Effective length of lower weights vector (number of nearest neighbours to consider). Should be either a positive integer, or a function that takes the size n of the complement of the class and returns a float, or None, which is resolved as n. All such values are rounded to the nearest integer in [1, n]. Alternatively, if this is 0, only the upper approximation is used.
- dissimilarity: str or float or (np.array -> float) or ((np.array, np.array) -> float) = ‘boscovich’
The dissimilarity measure to use. The similarity between two instances is calculated as 1 minus their dissimilarity.
A vector size measure np.array -> float induces a dissimilarity measure through application to y - x. A float is interpreted as Minkowski size with the corresponding value for p. For convenience, a number of popular measures can be referred to by name.
When a float or string is passed, the corresponding dissimilarity measure is automatically scaled to ensure that the dissimilarity of [1, 1, …, 1] with [0, 0, …, 0] is 1.
For instance, the default Boscovich norm (also known as cityblock, Manhattan or taxicab norm) normally assigns a dissimilarity that is the sum of the per-attribute differences. In this case, the scaling step divides by the number of dimensions, and we obtain a dissimilarity that is the mean of the per-attribute differences.
This can be prevented by explicitly passing a dissimilarity measure without scaling.
- nn_searchNeighbourSearchMethod = KDTree()
Nearest neighbour search algorithm to use.
- preprocessorsiterable = (RangeNormaliser(), )
Preprocessors to apply. The default range normaliser ensures that all features have range 1.
Notes
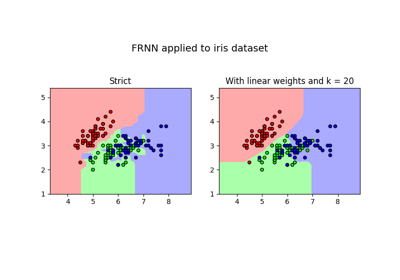
If upper_weights = lower_weights = None and upper_k = lower_k = 1, this is the original strict FRNN classification as presented in [1]. The use of OWA operators for the calculation of fuzzy rough sets was proposed in [2], and OWA operators were first explicitly combined with FRNN in [3].
References