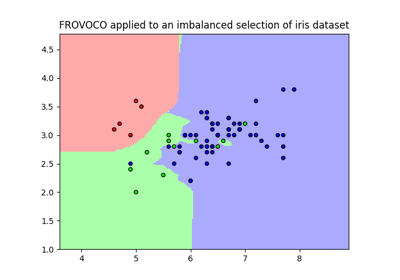
FROVOCO¶
- class frlearn.classifiers.FROVOCO(balanced_weights: ~typing.Callable[[int], ~numpy.array] = ExponentialWeights(base=2), balanced_k: int = <function at_most.<locals>._f>, imbalanced_weights: ~typing.Callable[[int], ~numpy.array] = LinearWeights(), imbalanced_k: int = <function multiple.<locals>._f>, ir_threshold: float = 9, dissimilarity: str = 'boscovich', nn_search: ~frlearn.neighbours.neighbour_search_methods.NeighbourSearchMethod = <frlearn.neighbours.neighbour_search_methods.KDTree object>, preprocessors=(<frlearn.statistics.feature_preprocessors.RangeNormaliser object>,))[source]¶
Implementation of the Fuzzy Rough OVO COmbination (FROVOCO) ensemble classifier [1].
FROVOCO decomposes muliclass classification into a number of one-vs-one and one-vs-rest comparisons. Depending on the imbalance ratio (ir) of each comparison, it uses different weights, following the IFROWANN scheme [2].
- Parameters
- balanced_weights(int -> np.array) or None = ExponentialWeights(base=2)
OWA weights to use when the imbalance ratio is not larger than ir_threshold. If None, only the balanced_kth neighbour is used.
- balanced_k: int or (int -> float) or None = at_most(16)
Length of the weights vector when the imbalance ratio is not larger than ir_threshold. Should be either a positive integer, or a function that takes the class size n and returns a float, or None, which is resolved as n. All such values are rounded to the nearest integer in [1, n]. Alternatively, if this is 0, only the lower approximation is used.
- imbalanced_weights(int -> np.array) or None = LinearWeights()
OWA weights to use when the imbalance ratio is larger than ir_threshold. If None, only the imbalanced_kth neighbour is used.
- imbalanced_k: int or (int -> float) or None = 0.1 * n
Length of the weights vector when the imbalance ratio is larger than ir_threshold. Effective length of lower weights vector (number of nearest neighbours to consider). Should be either a positive integer, or a function that takes the size n of the complement of the class and returns a float, or None, which is resolved as n. All such values are rounded to the nearest integer in [1, n]. Alternatively, if this is 0, only the upper approximation is used.
- ir_threshold: float or None = 9
Imbalance ratio threshold. Above this value, imbalanced_weights and imbalanced_k are used, otherwise balanced_weights and balanced_k. Set to None to only use balanced_weights and balanced_k.
- dissimilarity: str or float or (np.array -> float) or ((np.array, np.array) -> float) = ‘boscovich’
The dissimilarity measure to use. The similarity between two instances is calculated as 1 minus their dissimilarity.
A vector size measure np.array -> float induces a dissimilarity measure through application to y - x. A float is interpreted as Minkowski size with the corresponding value for p. For convenience, a number of popular measures can be referred to by name.
When a float or string is passed, the corresponding dissimilarity measure is automatically scaled to ensure that the dissimilarity of [1, 1, …, 1] with [0, 0, …, 0] is 1.
For instance, the default Boscovich norm (also known as cityblock, Manhattan or taxicab norm) normally assigns a dissimilarity that is the sum of the per-attribute differences. In this case, the scaling step divides by the number of dimensions, and we obtain a dissimilarity that is the mean of the per-attribute differences.
This can be prevented by explicitly passing a dissimilarity measure without scaling.
- nn_search: NeighbourSearchMethod = KDTree()
Nearest neighbour search algorithm to use.
- preprocessorsiterable = (RangeNormaliser(), )
Preprocessors to apply. The default range normaliser ensures that all features have range 1.
Notes
The original proposal uses full length exponential weight vectors, but since exponential weights decrease exponentially, the contribution of these additional weights to the classification result also decreases exponentially, and they are liable to corrupt the calculation due to their small size. Therefore, the default length of the exponential weight vector is 16. The original behaviour can be obtained by setting balanced_k to None.
References